问题描述
最近工作中发现有一些的应用程序导致系统的syscpu比较高,大概30%以上,对于我所在的公司来说,这么较高的sys cpu基本反映了当时运行的应用程序中应该有存在问题,如图:
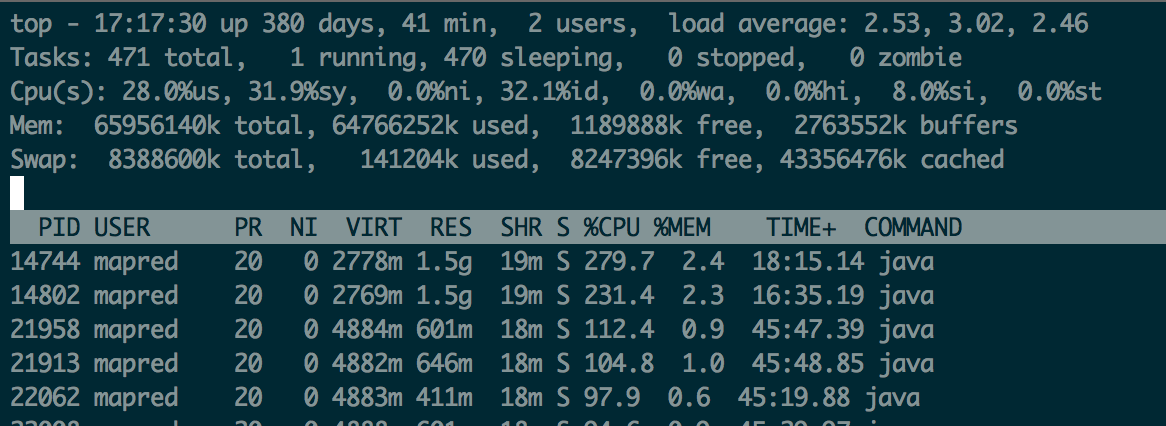
最近工作中发现有一些的应用程序导致系统的syscpu比较高,大概30%以上,对于我所在的公司来说,这么较高的sys cpu基本反映了当时运行的应用程序中应该有存在问题,如图:
hadoop RM,NN,DN,NM等支持动态在线设置log4j的日志级别,参考:daemonlog
改功能的原理是,利用log4j的Logger API中setLevel方法,在线修改当前Logger使用的日志级别。然而,这种方式并不适用所有的log4j的实现,它只能适用于Logger类中对外开放setLevel方法的,目前知道的两个logger的实现带有这个方法:
最近同事有需求要使用在hadoop 2.5.1的集群上使用snappy压缩。因为之前没有使用过snappy,所以没有在现有的集群上配置相关信息,于是乎就在官方和google查了一下相关的配置信息。之所以写这篇文章,主要是因为网上发的文章(尤其是中国的某些网站)的内容不靠谱,没有仔细阅读文档,就随便写一些不经过实践的文章来忽悠大家,导致大家如果根据他们的方式来安装和使用,可能会导致莫名其妙的问题。闲话不说了,写下我的操作过程
本方式为我根据hive的hook的特性开发一种部署方式,优点是针对单个客户端,
无需修改HIVE的源码,纯外接的方式来完成udf的部署,比临时udfs方便快捷且永久,且容易管理。
每个组或每个团队之间的udf彼此不受影响。
相信安装部署见:https://github.com/chaozi204/hive-udf-hook
集群中所有的nodemanager节点机器总是会报出警告信息 > 警告信息: 2015-07-29 00:44:57,785 WARN org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService: Remote Root Log Dir [/yarn-logs] already exist, but with incorrect permissions. Expected: [rwxrwxrwt], Found: [rwxr-xr-x]. The cluster may have problems with multiple users.
从警告的内容来看,似乎是目录的权限不匹配导致的,为了防止这个警告产生对集群的影响,于是排查本异常产生的原因。
记录工作中常用且常忘的那些方法
bash中取由变量生成的变量的值
1 2 3 4 | |
bash中取脚本的当前路径
1
| |
最近公司集群的存储空间过于紧张,一度低于5% 。集群空间一下子成为了集群瓶颈。再申请扩容无望的情况下,我们不得不着手于通过业务节省空间,
或者强制进行删除文件。
工作中,和同事无意中发现他的一份业务数据采用lzo + rcfile压缩后,压缩率超高,压缩前3G,压缩后200M。这种压缩率让我们感觉到异常(因为
通常情况下,这种压缩率级别在3倍左右),通过排查发现造成这种高压缩率的原因为:
1. 日记记录特别相似性(这是业务本身的特性),很多行除了小部分字段不同外,大部分一样.
2. 利用distribute by + sort by的hive特性,生成了hive表结果数据. 这样可以将相似的记录放在同一个reduce中,并根据特性字段排序
3. 利用rcfile的行列混合存储特性,就可以完成非常高的压缩率了(因为大部分列相同,所有就会有很高的压缩比)
最近在做一个项目中,同时使用了Java自身携带的java.util.Date类,和java.util.Calendar类来表示和处理时间。项目期间遇见了一个时间上的bug,主要是表示周几的问题上出现了差异。因为Java中,Date类的getDay方法,和Calendar.get(Calendar.DAY_OF_WEEK)返回的周信息表示分别为:
常用 Log4j 打印日志的代码:
利用Hive的正则匹配中文时需要注意:
例如:
select title from vid_title where type='my' and title rlike '^[\\\u4e00-\\\u9fa5]{1,2}$'
缩写是开发中利器,能够节约工程师打太多重复的代码好工具,作为一款比较牛叉的开发工具,Intellij当然包含了这个功能,而且还非常丰富,下面就记录如何查找默认定义的这些缩写,以及如何自定义缩写。 说明环境: Intellij IDEA 13
Hadoop Job在执行时非常缓慢(hadoop-1.0.0 和 hadoop-2.5.0集群中都有),且很多Map任务或reduce任务因为超时被kill掉,异常信息如下:
Task attempt_201406261559_894052_m_000269_1 failed to report status for 602 seconds. Killing!
protected void setup(Context context ) throws IOException, InterruptedException { }